TOP


Environment recognition using image processing
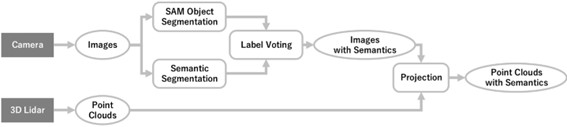
To enable autonomous mobile robots to understand their surroundings and take appropriate actions, object recognition using sensors is essential.
Typically, robots recognize objects in their surroundings as mere obstacles, but when equipped with information about "what the object is," such as a person or a car, they can make more advanced decisions.
This information about "what the object is" is referred to as semantic information, and the technology to identify it is known as semantic segmentation.
Cameras are generally used for semantic segmentation.
Cameras are highly effective in semantic segmentation because they can densely capture the texture information of objects.
However, since cameras rely on two-dimensional information, accurately obtaining the shapes of objects in three-dimensional space is challenging.
For measuring expansive spaces or complex three-dimensional shapes, 3D Lidar is more suitable.
While semantic segmentation can be performed using only 3D Lidar point clouds, its accuracy is inferior to that of cameras.
Therefore, we are researching a method that utilizes both cameras and 3D Lidar to accurately acquire both semantic information and three-dimensional shapes.

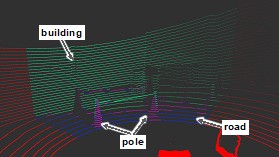
By performing semantic segmentation on camera images and projecting the results onto 3D Lidar point clouds, it is possible to overcome the shortcomings of both sensors and achieve higher-precision environmental recognition.
We are exploring various methods to improve the accuracy of semantic segmentation and projection onto 3D Lidar point clouds.
One of the challenges is the low reliability of segmentation boundaries, making it difficult to accurately align the boundaries with object shapes.
In particular, pixel-level errors near boundaries often cause ambiguity in detailed shapes.
To address this, we are considering techniques such as fine-tuning (training the learning model with new knowledge) to enhance accuracy.
Researcher

M2
Kei Miyagawa