TOP


画像処理を用いた環境認識
自律移動ロボットが周囲の環境を理解し適切な行動を取るには、センサーによる物体認識が不可欠です。
ロボットは通常、周囲の物体を単なる障害物として認識するが、人や車など「物体が何であるか」という情報を持つと、より高度な判断が可能になります。
この「物体が何であるか」という情報をセマンティック情報といい、それを識別する技術はセマンティックセグメンテーションと呼ばれます。
セマンティックセグメンテーションには、一般的にカメラが用いられます。
カメラは物体のテクスチャ情報を密に測定できるため、セマンティックセグメンテーションにおいて非常に有効です。
しかし、カメラは2次元情報に依存しているため、3次元空間での物体形状を高精度に取得することは難しいという課題があります。
広大な空間や複雑な3次元形状の測定には、3D Lidarが適しています。
3D Lidar点群のみでセマンティックセグメンテーションを行うことも可能ですが、その精度はカメラに劣ります。
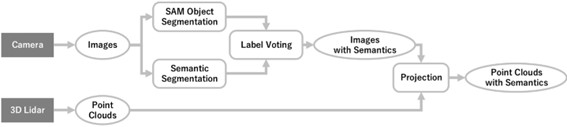
そこで我々は、カメラと3D Lidarの両方を使用することで、セマンティック情報と3次元形状の両方を高精度に取得する手法について研究しています。
カメラ画像に対してセマンティックセグメンテーションを行い、それを3D Lidar点群に投影することで、2つのセンサーの欠点を克服し、より高精度な環境認識が可能となります。

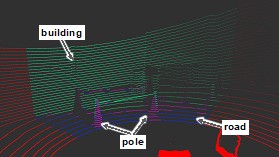
我々は、セマンティックセグメンテーション精度や3D Lidar点群への投影精度の向上を目的に、いくつかの手法を検討しています。
課題の1つはセグメンテーション境界の信頼性が低いことで、物体形状に正確に沿った境界を取得するのが難しい点です。
特に境界付近でのピクセル単位の誤差により、細部の形状が曖昧になることが多いため、ファインチューニング(学習モデルの新たな知識での訓練)などを検討して、精度向上に努めています。
研究の担当者

M2
宮川 慶